Data Architecture
How data is stored, materialized, and served within Method Platform.
Overview
Method’s Data Architecture is designed to solve four problems:
- Construct a knowledge graph from heterogeneous sources: Security data comes from dozens of different tools, APIs, and scanners, each with its own format. The Data Architecture normalizes this into a unified Ontology.
- Serve data in multiple form factors: Different consumers need data in different shapes.
- Track change over time: Security is temporal. The architecture records every observation immutably, enabling change detection, trend analysis, and historical investigation.
- Interoperable boundaries: Developers can add custom data sources and export data to external systems through standard interfaces.
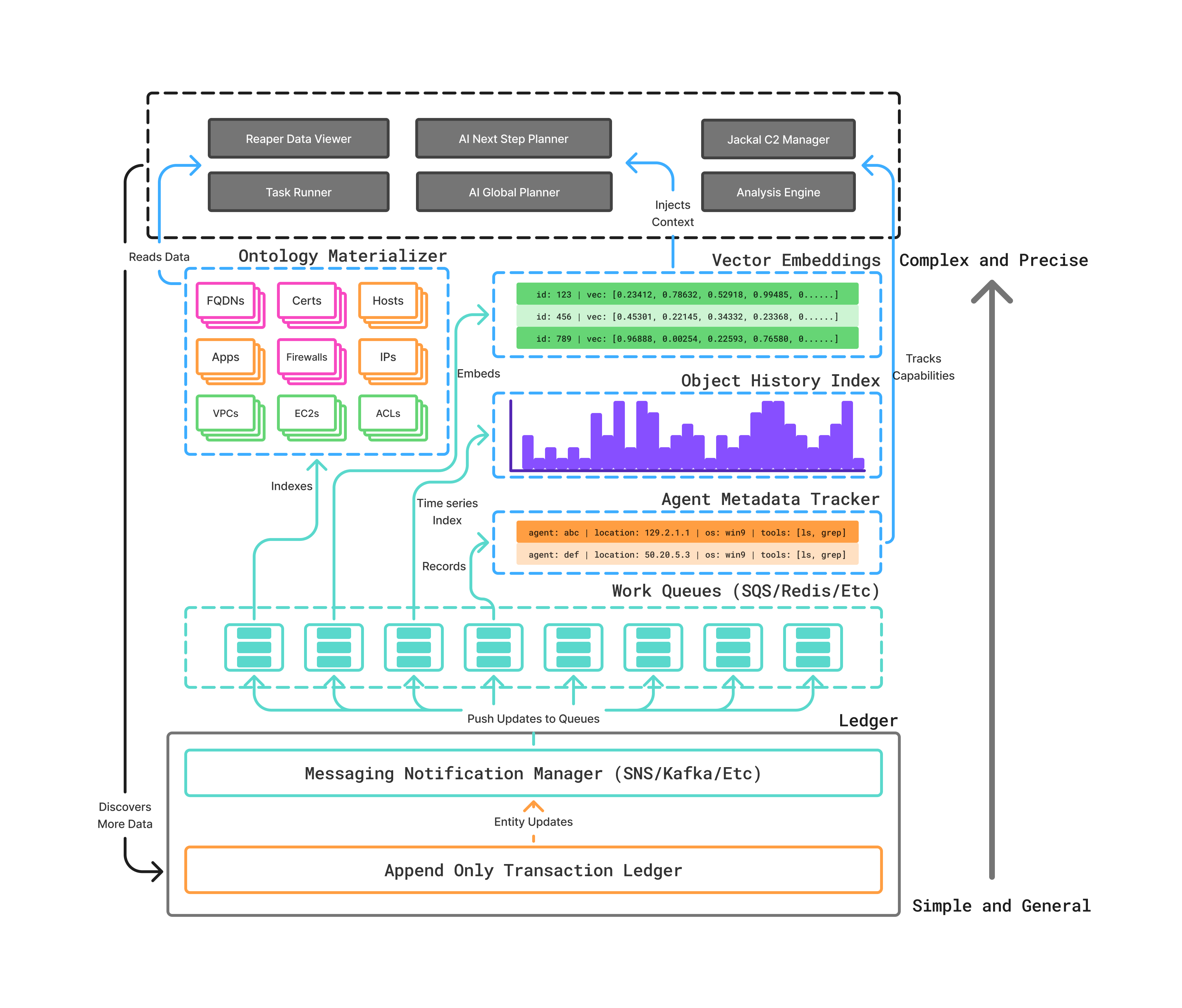
The Ledger
The Ledger is the foundation of Method’s data system. It is an append-only transaction store, meaning every observation from every Tool execution is recorded as an immutable entry.
The Ledger is intentionally general-purpose. It does not impose structure on the data it receives. This generality serves two purposes:
- Heterogeneous sources — Whether the input comes from an AWS API call, a Nessus scan, or a custom CLI tool, it is stored in the same way
- Complete history — Because entries are append-only, the Ledger preserves a full temporal record. You can answer questions like “when did this property first appear?” or “how has this host’s configuration changed over the last 90 days?”
The Ontology
The Ontology sits above the Ledger. It is a strongly typed knowledge graph that materializes raw Ledger data into structured, semantically rich entities and relationships.
The Ontology consists of:
- Objects: Typed entities (Hosts, Users, FQDNs, Cloud Accounts, etc.) with defined properties
- Links: Typed relationships between Objects (Is Administrator Of, Group Contains, Resolves To, etc.)
- Semantic typing: Every entity and relationship carries semantic meaning, making data legible to both humans and AI
The Ontology is not a static snapshot. It is continuously updated as new Ledger entries arrive, reflecting the real-time state of your environments.
Why this matters
This architecture has practical implications for how Method works:
- Cross-tool correlation — Data from different Tools is automatically linked in the Ontology. An IP address discovered by a cloud enumeration Tool is the same Object that a vulnerability scanner finds issues on.
- AI reliability — AI Agents operate on the strongly typed Ontology, not on raw unstructured data. This constrains their behavior to safe, predictable operations.
- Auditability — Every piece of data can be traced back through the Ontology to the Ledger entry that produced it, and from there to the specific Tool execution and command that generated it.